
Wat moed dat moet: mijn leven in flarden Simon Keizer



Non-fictie
"DeepSpeed Inference: Tensor Parallelism and Memory Efficiency for Large Models"
Serving large transformer models efficiently is no longer a matter of loading weights and hoping the hardware keeps up. This book is written for experienced ML engineers, systems practitioners, and infrastructure researchers who need a precise, production-oriented understanding of how DeepSpeed Inference scales models beyond single-device limits while preserving latency and throughput. It speaks directly to readers responsible for real deployment decisions, not simplified toy examples.
Across the book, you will learn how DeepSpeed’s inference stack is structured, how `init_inference` controls runtime behavior, and when tensor parallelism is the right scaling mechanism. It examines kernel injection, fused execution, checkpoint compatibility, automatic versus manual partitioning, ZeRO-Inference, heterogeneous memory, KV-cache offloading, and quantization as interconnected system choices rather than isolated features. The result is a rigorous framework for choosing deployment regimes, diagnosing bottlenecks, and engineering memory-efficient serving paths for very large models.
The treatment is version-aware and deliberately practical, helping readers navigate documentation drift, model support boundaries, and migration from classic DeepSpeed Inference concepts to newer FastGen-era framing. Readers should already be comfortable with transformer architectures, distributed GPU systems, and modern model-serving workflows. In return, the book offers a deeply technical, structured guide to the perfor
© 2026 NobleTrex Press (E-boek): 6610001214845
Verschijnt op
E-boek: 5 mei 2026
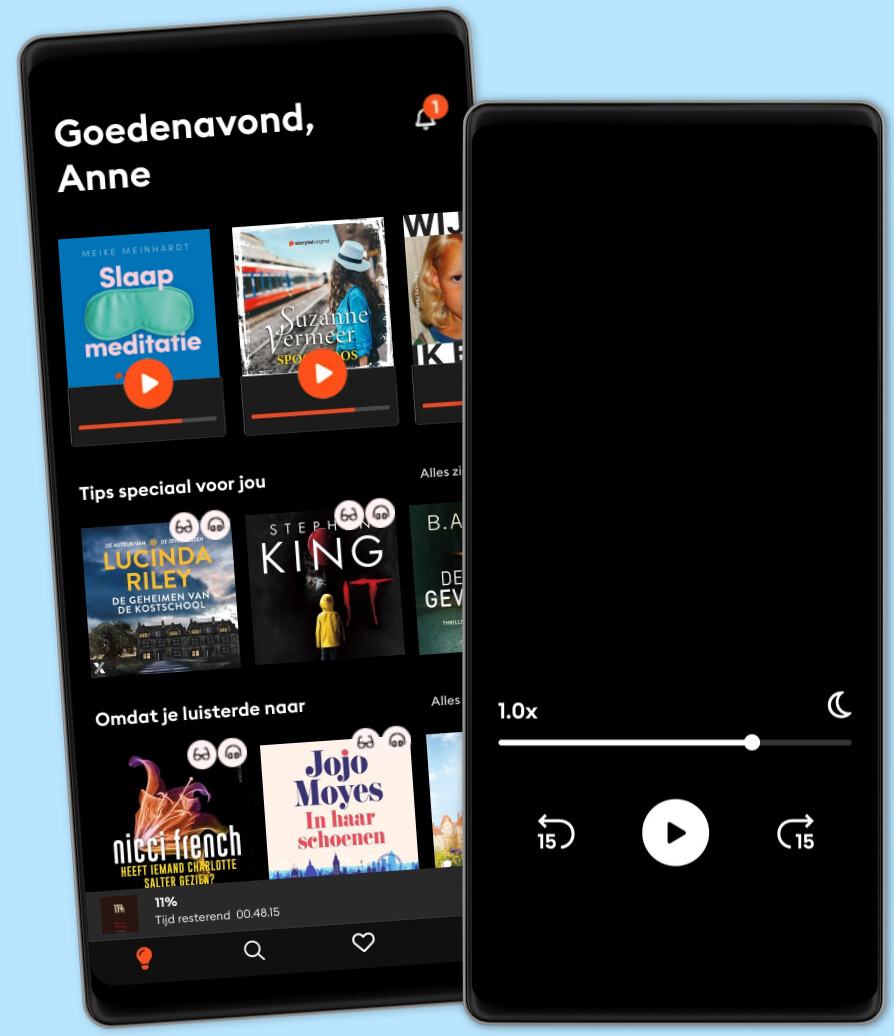
Kies het aantal uur en accounts dat bij jou past
Kids Mode - een veilige omgeving voor kinderen
Download verhalen voor offline toegang
Al 2,5 miljoen abonnees wereldwijd
★★★★★ 4,7 in de App Store
Voor wie onbeperkt wil luisteren en lezen.
€13.99 /30 dagen
1 account
Onbeperkt lezen en luisteren
Meer dan 1 miljoen luisterboeken en ebooks
Altijd opzegbaar
Voor wie zo nu en dan wil luisteren en lezen.
€9.99 /30 dagen
1 account
30 uur/30 dagen
Meer dan 1 miljoen luisterboeken en ebooks
Altijd opzegbaar
Voor wie Storytel wil proberen.
€7.99 /30 dagen
1 account
10 uur/30 dagen
Spaar ongebruikte uren op tot 50 uur
Meer dan 1 miljoen luisterboeken en ebooks
Altijd opzegbaar
Voor wie verhalen met familie en vrienden wil delen.
Vanaf €18.99 /30 dagen
2-3 accounts
Onbeperkt lezen en luisteren
Meer dan 1 miljoen luisterboeken en ebooks
Altijd opzegbaar
Jij + 1 familielid
2 accounts€18.99 /30 dagen