
Al het blauw van de hemel Mélissa Da Costa
 4.7
4.7
Ontdek Storytel nu 14 dagen gratis. Meer dan 1 miljoen luisterboeken en ebooks in één app.
Non-fictie
Most data engineers know that performance issues in a distributed computing environment can easily lead to issues impacting the overall efficiency and effectiveness of data engineering tasks. While Python remains a popular choice for data engineering due to its ease of use, Scala shines in scenarios where the performance of distributed data processing is paramount. This book will teach you how to leverage the Scala programming language on the Spark framework and use the latest cloud technologies to build continuous and triggered data pipelines. You’ll do this by setting up a data engineering environment for local development and scalable distributed cloud deployments using data engineering best practices, test-driven development, and CI/CD. You’ll also get to grips with DataFrame API, Dataset API, and Spark SQL API and its use. Data profiling and quality in Scala will also be covered, alongside techniques for orchestrating and performance tuning your end-to-end pipelines to deliver data to your end users. By the end of this book, you will be able to build streaming and batch data pipelines using Scala while following software engineering best practices.
© 2024 Packt Publishing (Ebook): 9781804614327
Verschijnt op
Ebook: 31 januari 2024
4.73.7 3.63.23.84.64.64.74.44.34.44.34.24.74.5
3.63.23.84.64.64.74.44.34.44.34.24.74.5Voor ieder een passend abonnement
Kies het aantal uur en accounts dat bij jou past
Download verhalen voor offline toegang
Kids Mode - een veilige omgeving voor kinderen
Voor wie onbeperkt wil luisteren en lezen.
€13.99 /30 dagen
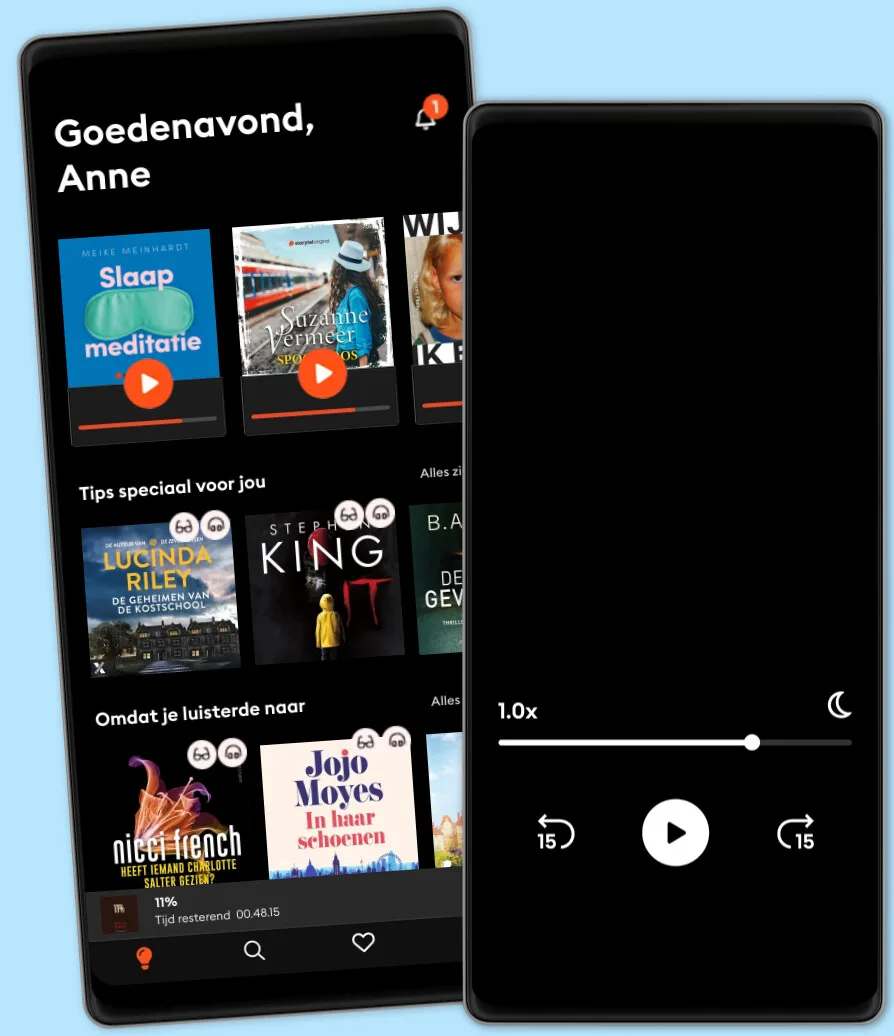
Meer dan 1 miljoen luisterboeken en ebooks
Altijd opzegbaar
Voor wie zo nu en dan wil luisteren en lezen.
€9.99 /30 dagen
Meer dan 1 miljoen luisterboeken en ebooks
Altijd opzegbaar
Voor wie Storytel wil proberen.
€7.99 /30 dagen
Spaar ongebruikte uren op tot 50 uur
Meer dan 1 miljoen luisterboeken en ebooks
Altijd opzegbaar
Voor wie verhalen met familie en vrienden wil delen.
Vanaf €18.99 /maand
Meer dan 1 miljoen luisterboeken en ebooks
Altijd opzegbaar
€18.99 /30 dagen
Nederlands
Nederland