
Konstnären Dag Öhrlund
 4.1
4.1

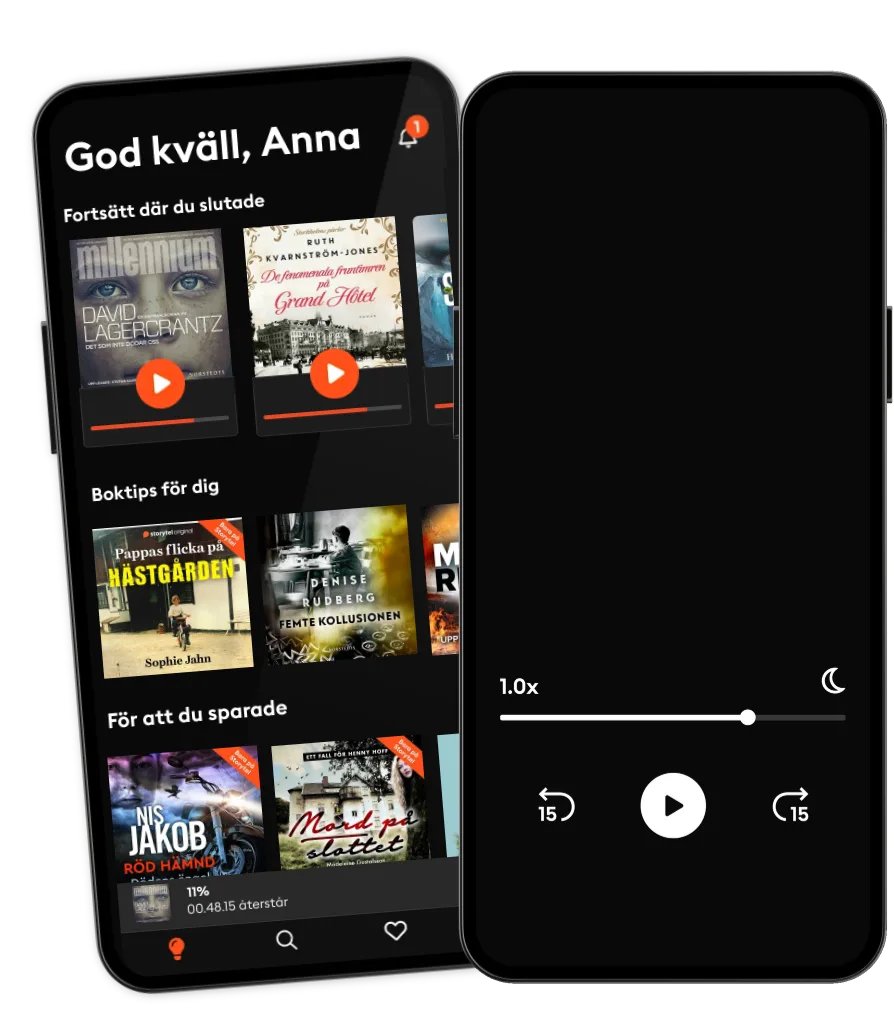
Kliv in i en oändlig värld av stories
Fakta
Most data engineers know that performance issues in a distributed computing environment can easily lead to issues impacting the overall efficiency and effectiveness of data engineering tasks. While Python remains a popular choice for data engineering due to its ease of use, Scala shines in scenarios where the performance of distributed data processing is paramount. This book will teach you how to leverage the Scala programming language on the Spark framework and use the latest cloud technologies to build continuous and triggered data pipelines. You’ll do this by setting up a data engineering environment for local development and scalable distributed cloud deployments using data engineering best practices, test-driven development, and CI/CD. You’ll also get to grips with DataFrame API, Dataset API, and Spark SQL API and its use. Data profiling and quality in Scala will also be covered, alongside techniques for orchestrating and performance tuning your end-to-end pipelines to deliver data to your end users. By the end of this book, you will be able to build streaming and batch data pipelines using Scala while following software engineering best practices.
© 2024 Packt Publishing (E-bok): 9781804614327
Utgivningsdatum
E-bok: 31 januari 2024
4.144.3444.14.34.44.23.73.93.74.13.83.81 miljon stories
Lyssna och läs offline
Exklusiva nyheter varje vecka
Kids Mode (barnsäker miljö)
Lyssna och läs ofta.
169 kr /månad
Exklusivt innehåll varje vecka
Avsluta när du vill
Obegränsad lyssning på podcasts
Lyssna och läs obegränsat.
229 kr /månad
Exklusivt innehåll varje vecka
Avsluta när du vill
Obegränsad lyssning på podcasts
Dela stories med hela familjen.
Från 239 kr /månad
Exklusivt innehåll varje vecka
Avsluta när du vill
Obegränsad lyssning på podcasts
239 kr /månad
Lyssna och läs ibland – spara dina olyssnade timmar.
99 kr /månad
Spara upp till 100 olyssnade timmar
Exklusivt innehåll varje vecka
Avsluta när du vill
Obegränsad lyssning på podcasts
Svenska
Sverige